知识点 Check List#
计算机网络#
TCP 三次握手 ✔️#
由 client 执行 connect(3) 触发。
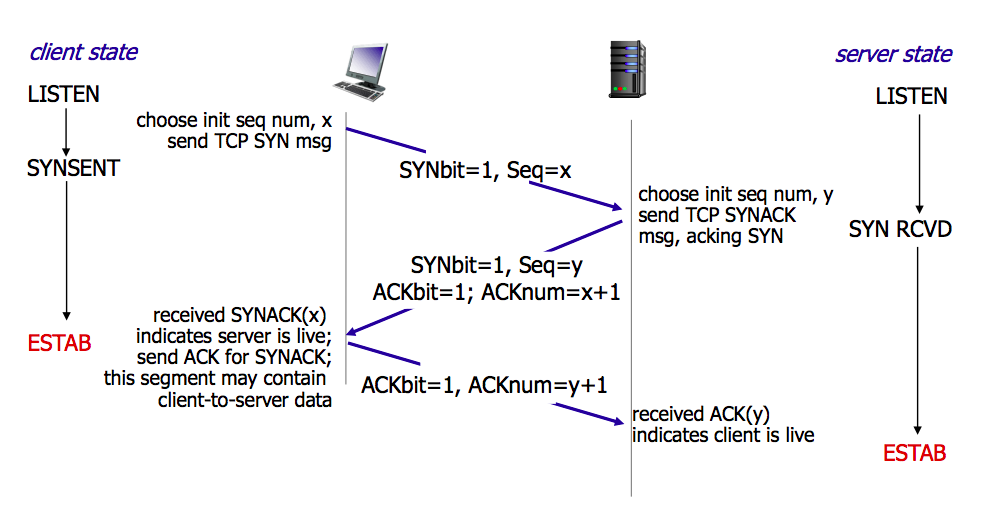
作用:
确认双方的接收和发送能力是否正常
协商初始序列号,交换窗口大小等
- 半连接队列
服务端第一次受到 SYN 包(
SYN_RCVD)的队列
TCP 四次挥手 ✔️#
由任意一方执行 close(3) 触发。
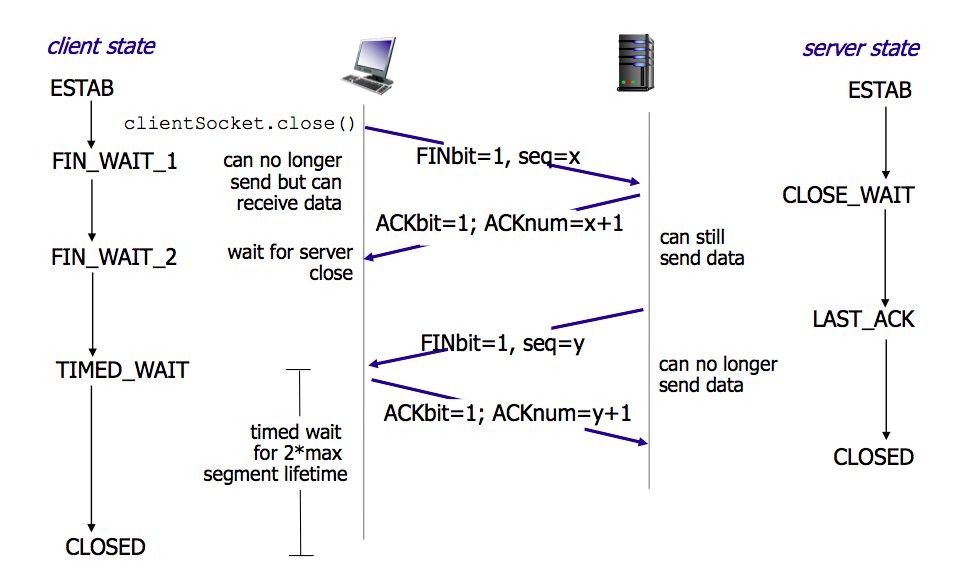
- 为什么是 4 次
被动端(被 close 那一端)要额外的准备才能关闭连接,主动端发的 FIN 相当于一次 notification。 当被动端准备好了会发 FIN,这个 FIN 也需要 ACK
- Server 大量
TIME_WAIT Server 端主动关连接导致的,可能会耗尽可用的端口
- 解决
连接复用 要求客户端关连接
- Server 大量
CLOSE_WAIT Client 端主动关连接,Server 没有发第二个 FIN
TCP UDP 区别 ✔️#
- TCP
全双工,面向连接,可靠,一对一通信
- UDP
无连接,不可靠,可多播、广播
select,epoll ✔️#
- 📖 Select_(Unix)
是个单独的系统调用
复杂度 \(O(n)\)
连接数:
FD_SETSIZE = 8
- 📖 Epoll
是个模块,由三个系统调用组成
底层为红黑树,复杂度 \(O(log_n)\)
连接数:API 上无限制
边沿触发(异步推荐)、状态触发
Web#
HTTPS 原理 ✔️#
- 对称加密
- Pros:
计算量小、加密速度快、加密效率高
- Cons:
需要协商密钥,也就无法避免密钥的传输
一对多通信时需要使用多对密钥
- 非对称加密
- Pros:
加密和解密使用不同的钥匙
- Cons:
计算量比较大(硬件加速卡)
- 通信过程
证书验证
数据传输阶段
非对称加密(协商对称密钥)
对称加密(传输数据)
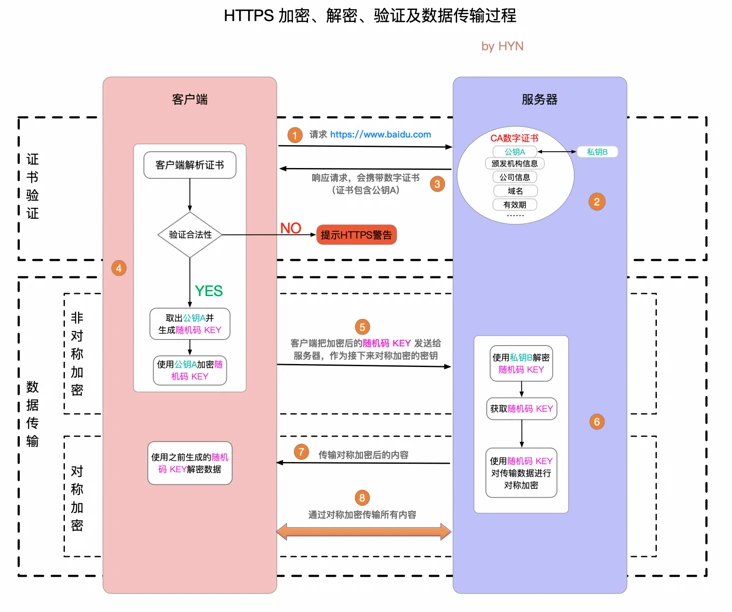
HTTPS 加密、解密、验证及数据传输过程#
分布式#
Map-Reduce 概述 ✔️#
映射(可并行) -> 归纳
分布式 ID 生成 ✔️#
基本要求是全局唯一 —— 不冲突。
- UUID / 自己随机生成
- pros:
不依赖外部服务
- cons:
业务价值不大
不利于储存和索引
不能趋势递增
- 单数据库自增 ID
- pros:
支持递增
- cons:
单点故障
不利于储存和索引
不能趋势递增
- 数据库集群自增 ID
- pros:
支持递增
不存在单点问题
- cons:
数据库集群方案麻烦
扩容麻烦
- 避免重复 ID
为不同实例制定不同的 ID 起始值,协商步长
- 分配号段
业界主流方式之一,就是一个 ID Quota Server,Client 每次取一段,用完再申请
- pros:
对数据库压力小
- cons:
要不集群化还是单点
朴素的实现中,没有把内存中的ID消费完重启服务,则会产生重复的ID
- Redis
优缺点同数据库
需要考虑持久化的问题
- Snowflake 算法
Timestamp + Machine ID + Data Center ID + Auto Increasement Num
- pros:
不依赖外部服务
便于链路追踪
支持递增
- cons:
int64 需要小心处理(前端)
选主#
脑裂#
CAP ✔️#
对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
分区容错性(Partition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择)
—— 📖 CAP定理
P(分区容错性)是说这个系统要允许分区?
分布式锁 ✔️#
- 场景
分布式事务
避免重复工作
保证结果正确
- 额外特性
- 公平锁:
各个节点均摊锁带来的工作量
- 可重入:
已经持有锁的节点再锁住自己没意义
- 超时:
持有锁的节点故障应让锁得到释放
- 实现
mysql psql 关系型数据库:事务
redis redlock codis 非关系型数据库:SETNX (set if not exist)
etcd/zookeeper 集群协同:CAS
chubby 专用的锁服务
分布式定时器 ✔️#
- 实现
公平的分布式锁实现:etcd
环形队列/时间轮
一致性级别 ✔️#
- 强/线性一致性
任何一次读都能读到某个数据的最近一次写的数据
系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致
- 最终一致性
系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态
- 顺序一致性
所有的进程都以相同的顺序看到所有的修改。
读操作未必能够及时得到此前其他进程对同一数据的写更新,但是每个进程读到的该数据不同值的顺序却是一致的。
两阶段提交#
海量数据 TopN#
Paxos#
一种基于消息传递且具有高度容错特性的共识(consensus)算法。
—— 📖 Paxos算法
- 分布式系统通信模型
共享内存(Shared memory)
消息传递(Messages passing)
好复杂…… 看看就行吧,不强求懂了。
Raft ✔️#
Raft能为在计算机集群之间部署有限状态机提供一种通用方法,并确保集群内的任意节点在某种状态转换上保持一致。
…
集群内的节点都对选举出的领袖采取信任,因此Raft不是一种拜占庭容错算法。
—— 📖 Raft
- 子问题
领袖选举(Leader Election)
记录复写(Log Replication)
安全性(Safety)
看 Wiki 即可,好懂多了。
外部排序#
关系型数据库#
数据库范式 ✔️#
- 1NF
原子性,属性都不可再分
- 2NF
非主属性完全依赖主属性
- 3NF
非主键属性之间独立无关
- BCNF
任何属性(包括非主属性和主属性)都不能被非主属性所决定。
ACID ✔️#
- A:
Atomicity 原子性 锁
- C:
Consistency 一致性
- I:
Isolation 隔离性
- D:
Durability 持久性 数据库的 redo log
事务隔离级别#
- Read Uncommitted:
允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
- Read Committed:
只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
- Repeated Read:
可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
- Serializable:
完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
表级别锁和行级别锁
幻读?
索引 ✔️#
- 作用
提高查询效率
实现数据库约束
- 代价
需要额外的空间
插入、更新和删除记录时,需要同时修改索引
- 类型
哈希索引:等值查询效率高,不支持区间查询
顺序索引 查询效率高(二分),只适用于静态存储引擎
多路搜索树索引:
- 按结构分类
聚簇索引
非聚簇索引
局部性原理
分表与分片#
并发控制 ✔️#
数据库中的并发控制的任务是确保在多个事务同时访问数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。
- 乐观锁
假设不冲突,冲突则回滚:
乐观锁假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
乐观并发控制多数用于数据争用不大、冲突较少的环境中,这种环境中,偶尔回滚事务的成本会低于读取数据时锁定数据的成本,因此可以获得比其他并发控制方法更高的吞吐量。
—— 📖 乐观并发控制
- 悲观锁
串行的事务控制:
悲观锁可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作读某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
—— 📖 悲观并发控制
- 公平锁
多个线程按照申请锁的顺序去获得锁
- Pros:
所有的线程都能得到资源,不会饿死在队列中
- Cons:
吞吐量下降,队列里面除了第一个线程,其他的线程都会阻塞,唤醒开销大
- 非公平锁
多个线程不按照申请锁的顺序去获得锁,而是同时直接去尝试获取锁
- Pros:
效率稍高
- Pros:
可能导致饥饿
- MVCC
乐观的版本控制:
每个事务读到的数据项都是一个历史快照(snapshot)并依赖于实现的隔离级别。写操作不覆盖已有数据项,而是创建一个新的版本,直至所在操作提交时才变为可见
MVCC使用时间戳 (TS), 或“自动增量的事务ID”实现“事务一致性”。MVCC可以确保每个事务(T)通常不必“读等待”数据库对象(P)。这通过对象有多个版本,每个版本有创建时间戳 与废止时间戳 (WTS)做到的。
事务Ti读取对象(P)时,只有比事务Ti的时间戳早,但是时间上最接近事务Ti的对象版本可见,且该版本应该没有被废止。
事务Ti写入对象P时,如果还有事务Tk要写入同一对象,则(Ti)必须早于(Tk),即 (Ti) < (Tk),才能成功。[2]
MVCC可以无锁实现。
—— 📖 多版本并发控制
架构#
微服务概述#
服务降级#
服务重试#
幂等性
限流器 ✔️#
固定时间窗口计数
滑动时间窗口计数
Token Bucket:水 = 令牌
Leaky Bucket:水 = 请求
参见
流量整形
负载均衡 ✔️#
- 方向
客户端侧
反向代理侧
- 原理
Round Robin
传统的哈希取模算法
一致性哈希
基于连接数
基于会话
- 硬件
F5
- 软件
Nginx 7 层
envoyproxy 4 层、7 层
HAproxy
LVS(Linux Virtual Server)4 层
一致性哈希 ✔️#
解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系
环状哈希
虚拟节点
查找距离这个对象的 hash 值最近的节点的 hash(在排好序的哈希数组里二分),即是这个对象所属的节点
灰度测试#
A/B Test
实现
并发和吞吐#
协程 异步 读写分离
故障转移#
中间件#
Redis 等缓存#
Kafka#
基于 topic 的订阅模式。
- 投递语义
- at most once:
至多一次,消息可能会丢,但不会重复
- at least once:
至少一次,消息肯定不会丢失,但可能重复
- exactly once:
有且只有一次,消息不丢失不重复,且只消费一次。
etcd zk 等集群协同#
操作系统#
进程、线程和协程 ✔️#
进程有独立地址空间,线程无
协程:纯粹的用户态实现
fork & exec ✔️#
没啥好说。
进程间通信方式概述 ✔️#
文件
信号
信号量(PV 原语维护一个临界区)
Unix socket
Message Queue
管道
mkfifo命名管道(传统管道属于匿名管道,其生存期不超过创建管道的进程的生存期。但命名管道的生存期可以与操作系统运行期一样长)Shared Memory
Mapped File
DMA ✔️#
Direct Memory Access,允许某些电脑内部的硬件子系统(电脑外设),可以独立地直接读写系统内存,而不需 CPU 介入处理 。
每一个DMA通道有一个16位地址寄存器和一个16位计数寄存器。要初始化资料传输时,设备驱动程序一起设置DMA通道的地址和计数寄存器,以及资料传输的方向,读取或写入。然后指示DMA硬件开始这个传输动作。当传输结束的时候,设备就会以中断的方式通知中央处理器。
Huge Page ✔️#
4K -> ??
TLB 需求减少 cache missing 减少
减少了页面数量,页表也少了一级,使得缺页中断的数量大大减少,缺页中断的处理效率也有了提高
透明巨型页。
死锁 ✔️#
讲一下操作系统死锁是如何发生的,以及如何解决死锁
Golang#
调度问题 ✔️#
- 线程模型
- N:1:
可以很快的进行上下文切换,但是不能利用多核系统(multi-core systems)的优势
- 1:1:
能够利用机器上的所有核心的优势,但是上下文切换非常慢,因为不得不使用系统调用
- M:N:
可以快速进行上下文切换,并且还能利用你系统上所有的核心的优势。主要的缺点是它增加了调度器的复杂性
- M.P.G
- M:
OS 线程
- P:
Processor,可以把它看作在一个单线程上运行代码的调度器的一个本地化版本,携带一个 Goroutine 的 runqueue
- G:
Goroutine
P 就是
runtime.GOMAXPROCS里的 PROCS.- M 为什么不是 P
如果正在运行的 M 为某种原因需要阻塞的时候,我们可以把 P 移交给其它 M
Go 程序要在多线程上运行的原因就是因为要处理系统调用,哪怕
GOMAXPROCS等于 1- 偷取 runqueue
为了保持运行Go代码,一个上下文能够从全局runqueue中获取goroutines,但是如果全局runqueue中也没有goroutines了,那么上下文就不得不从其它地方获取goroutines了。
垃圾回收#
经典 GC 算法 ✔️#
- 经典的 GC 算法
引用计数(reference counting)
标记-清扫(mark & sweep)
节点复制(Copying Garbage Collection)
分代收集(Generational Garbage Collection)。
- 引用计数
- Pros
渐进式的,能够将内存管理的开销分布到整个程序之中
易于实现
回收速度快
- Cons
不能处理循环引用(引入强弱引用可破)
降低运行效率
free list 实现的话不是 cache-friendly
- 标记-清扫
内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是 STW,转而执行垃圾回收程序。垃圾回收程序对所有的存活单元进行一次全局遍历确定哪些单元可以回收。算法分两个部分:标记(mark)和清扫(sweep)。标记阶段表明所有的存活单元,清扫阶段将垃圾单元回收。
- Pros
支持循环引用
运行时开销小
- Cons
需要 STW
- 三色标记
是「标记-清扫」的变种,对标记阶段进行了改进:
起初所有对象都是白色
从根出发扫描所有可达对象,标记为灰色,放入待处理队列
从队列取出灰色对象,将其引用对象标记为灰色放入队列,自身标记为黑色
重复 3,直到灰色对象队列为空。此时白色对象即为垃圾,进行回收
- Pros
能够让用户程序和 标记 并发的进行(?),减少 STW 的时间
备注
标记期间有新的对象分配/释放怎么办?
通过设置写屏障(write barriar)记录下来,标记完 STW 再检查一遍
备注
Golang GC 使用三色标记法
- 节点复制
- Pros
无内存碎片
allocate 简单,通过递增自由空间指针即可
- Cons
总有一半的内存空间处于浪费状态
基于追踪的垃圾回收算法(标记-清扫、节点复制)一个主要问题是在生命周期较长的对象上浪费时间(长生命周期的对象是不需要频繁扫描的)。同时,内存分配存在这么一个事实:
most object die young [Ungar, 1984]
- 分代收集
分代垃圾回收算法将对象按生命周期长短存放到堆上的两个(或者更多)区域,这些区域就是分代(generation)。对于新生代的区域的垃圾回收频率要明显高于老年代区域。
分配对象的时候从新生代里面分配,如果后面发现对象的生命周期较长,则将其移到老年代,这个过程叫做 promote。随着不断 promote,最后新生代的大小在整个堆的占用比例不会特别大。收集的时候集中主要精力在新生代就会相对来说效率更高,STW 时间也会更短。
- Pros
性能优
- Cons
实现复杂
Go 的垃圾回收 ✔️#
- 何时触发 GC 检测
- 被动触发:
在堆上分配大于 32K byte 对象时触发 GC 检测
- 主动触发:
调用
rumtime.GC()
- GC 触发条件
forceTrigger || memstats.heap_live >= memstats.gc_trigger当前堆上的活跃对象大于我们初始化时候设置的 GC 触发阈值
memstats.gc_trigger在gcinit()时被设置- 两次 mark
从 root 开始遍历,标记为灰色。遍历灰色队列
re-scan 全局指针和栈。因为 mark 和用户程序是并行的,所以在过程 1 的时候可能会有新的对象分配,这个时候就需要通过写屏障(write barrier)记录下来。re-scan 再完成检查
- 两次 STW
GC 将要开始的一些准备工作,比如 enable write barrier
re-scan,如果这个时候没有 STW,那么 mark 将无休止
- 写屏障
收集 mark 期间的对象分配情况
- Dive in to code
- gcBgMarkStartWorkers:
为每个 P(线程上的本地调度器)启动一个 gcMarkWoker
- gcDrain:
Mark 阶段的标记代码主要实现
内存管理#
逃逸分析: go run with -gcflags '-m -l'
- 如何得知变量是分配在栈(stack)上还是堆(heap)上?
不需要关心,由 go 内部决定
- 多级分配器
- mcache:
per-P cache,可以认为是 local cache,不需要加锁
- mcentral:
全局 cache,mcache 不够用的时候向 mcentral 申请。
- mheap:
当 mcentral 也不够用的时候,通过 mheap 向操作系统申请。
Channel ✔️#
sync.Mutex ✔️#
互斥、自旋(正常状态)、公平(饥饿状态)。
- 自旋
不 park,直接 CAS 抢
mutexWoken位,而非被唤醒后再抢- 限制条件
P > 0
自旋次数有限
P 的 runq 为空:没有待调度的 G
- 公平
等待时间超过
starvationThresholdNs饥饿模式下 Unlock,仅唤醒第一个 waiter,一定能抢锁成功
还是蛮复杂的,记个差不多就行。
sync.RWMutex ✔️#
- 读写问题的三大类
- 读优先
占有锁时,后来的读进程可以立即获得锁
- Pros:
可以提高并发性能(后来的读进程不需要等待)
- Cons:
读进程过多,会导致写进程一直处于等待中,出现写饥饿现象
- 写优先(RWMutex)
优先是指如果有写进程在等待锁,会阻止后来的进程获得锁
- Pros:
写饥饿的问题
不区分优先级
Golang 的实现是写的互斥锁 + 读计数器,感觉有点别扭。
一个我认为应当 detect 但实际上没还有的错误用法:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mu sync.RWMutex
go func() {
fmt.Println("Lock")
mu.Lock()
fmt.Println("Locked")
defer func() {
fmt.Println("Unlock")
mu.Unlock()
fmt.Println("Unlocked")
}()
time.Sleep(5 * time.Second)
}()
time.Sleep(100 * time.Millisecond)
go func() {
time.Sleep(100 * time.Millisecond)
fmt.Println("RUnlock")
mu.RUnlock()
fmt.Println("RUnlocked")
}()
fmt.Println("RLock")
mu.RLock()
fmt.Println("RLocked")
}
sync.Map ✔️#
- 检测 “concurrent map read and map write”
用 hashWriting bit 表示当前是否在进行写操作
Defer#
小坑点:参数是提前求值的
struct runtime._defer 组成了一条 defer link list。
- <1.13:
堆上分配
- >=1.13:
栈上分配
- <1.14:
Open coded
&^ 操作符 ✔️#
日常是很少用上,标准库代码里见得多。
Bit clear,a &^ b == a & ^b。
interface{}#
内存泄漏#
死锁检测 ✔️#
当两个以上的运算单元,双方都在等待对方停止运行,以获取系统资源,但是没有一方提前退出时,就称为死锁
—— 📖 死锁
- 死锁的条件:
- 禁止抢占:
系统资源不能被强制从一个进程中退出。
- 持有和等待:
一个进程可以在等待时持有系统资源。
- 互斥:
资源只能同时分配给一个行程,无法多个行程共享。
- 循环等待:
一系列进程互相持有其他进程所需要的资源。
fatal error: all goroutines are asleep - deadlock!
runtime stack
参见
避免死锁:
使用无锁的结构
约定资源的使用和释放
超时放弃
非瓶颈不用细粒度所,避免复杂情况
数据竞争#
sync.Cond 的虚假唤醒 ✔️#
因为 condition 的判断是用户代码,在 Wait() 返回之后,因此只能要求用户用忙等的方式等到 condition 满足的时刻:
Because c.L is not locked when Wait first resumes, the caller typically cannot assume that the condition is true when Wait returns. Instead, the caller should Wait in a loop:
c.L.Lock() for !condition() { c.Wait() } // ... make use of condition ... c.L.Unlock()
云原生#
k8s#
Docker ✔️#
- 共享内核
Docker image 里不包含内核,程序共享宿主机内核
- Namespace
用 unshare(1) 创建
- Mount:
每个容器能看到不同的文件系统层次结构
- UTS:
每个容器可以有自己的 hostname 和 domainame
- IPC:
每个容器有其自己的 sysvipc(7) 和 mq_overview(7) 队列,只有在同一个 IPC namespace 的进程之间才能互相通信
- PID:
每个 PID namespace 中的进程可以有其独立的 PID,也使得容器中的每个进程有两个 PID
- Network:
每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端口号等
- User:
每个 container 可以有不同的 user 和 group id;一个 host 上的非特权用户可以成为 user namespace 中的特权用户
- Cgroup
通过 sysfs
/sys/fs/cgroup控制,创建目录,并指定 PID,如:/sys/fs/cgroup/cpu/docker/03dd196f415276375f754d51ce29b418b170bd92d88c5e420d6901c32f93dc14or
systemd-cgls- Resource limitation:
限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization:
优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting:
一些审计或一些统计,主要目的是为了计费。
- Control:
挂起进程,恢复执行进程。
AUFS、OverlayFS、VFS、Brtfs
- OverlayFS
lowerdir、uperdir、merged,其中lowerdir是只读的image layer,其实就是rootfs,
lowerdir是可以有多个目录。upperdir则是在lowerdir之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容器数据更改都发生在这里层, 对比示例中的C。最后 merged 目录是容器的挂载点,也就是给用户暴露的统一视角
- 进程模型
- dockerd:
和 docker-cli 通信,管理镜像
- containerd:
管理容器
- container-shim:
通过 runC 运行容器
隔离#
- 网络:
namespace
虚拟化#
KVM ✔️#
Kernel-based Virtual Machine
在 Linux 中,通过设备 /dev/kvm + ioctl 进行通信。
- CPU 虚拟化
VMX 指令集
VMX的非根操作模式是一个相对受限的执行环境,为了适应虚拟化而专门做了一定的修改;在客户机中执行的一些特殊的敏感指令或者一些异常会触发“VM Exit”退到虚拟机监控器中,从而运行在VMX根模式。正是这样的限制,让虚拟机监控器保持了对处理器资源的控制 [1]
- 内存虚拟化
CR3 控制寄存器 存放页目录地址
给虚拟客户机操作系统提供一个从0地址开始的连续物理内存空间,同时在多个客户机之间实现隔离和调度
- Without KVM:
影子页表(Shadow Page Table)
- Within KVM:
EPT(Extended Page Tables,扩展页表) EPT的控制权在 Hypervisor 掌握,因此不需要 VMexit,只有当CPU工作在非根模式时才参与内存地址的转换
VPID(Virtual-processor identifier)
TLB: (Translation Lookaside Buffer)用于改进虚拟地址到物理地址转换速度的缓存
- IO 虚拟化
模拟:在 Hypervisor 中模拟一个传统的I/O设备的特性
虚拟化专用接口:virtio
直接分配设备:
VT-d(Virtualization Technology For Directed I/O):I/O设备分配、DMA重定向、中断重定向、中断投递等
SR-IOV
设备共享:需要设备支持多个虚拟机功能接口
- 架构
KVM虚拟化的核心主要由以下两个模块组成:
内核模块,它属于标准Linux内核的一部分,是一个专门提供虚拟化功能的模块,主要负责CPU和内存的虚拟化,包括:客户机的创建、虚拟内存的分配、CPU执行模式的切换、vCPU寄存器的访问、vCPU的执行
QEMU用户态工具,它是一个普通的Linux进程,为客户机提供设备模拟的功能,包括模拟BIOS、PCI/PCIE总线、磁盘、网卡、显卡、声卡、键盘、鼠标等。同时它通过ioctl系统调用与内核态的KVM模块进行交互。 在KVM虚拟化架构下,每个客户机就是一个QEMU进程,在一个宿主机上有多少个虚拟机就会有多少个QEMU进程;客户机中的每一个虚拟CPU对应QEMU进程中的一个执行线程
libvirt#
是一套用于管理硬件虚拟化的开源API、守护进程与管理工具
流处理#
Flink CheckPoint#
Operator State Keyed State
PLER vs Flink#
CheckPoint
UDF
Watermark
逻辑计划优化#
常量折叠
列裁剪
乱序元素#
- URL:
- Watermark:
根据流的情况制定开启和关闭策略
- allowLateNess:
延迟窗口关闭时间
- sideOutPut:
指定窗口已经彻底关闭后,就会把所有过期延迟数据放到侧输出流,让用户决定如何处理
算法#
- 树
树的遍历 ✔️
平衡树
二叉堆
- 动态规划
最长上升子序列 ✔️
最长公共子序列 ✔️
最长回文串 ✔️
01 背包 ✔️
脚注
如果你有任何意见,请在此评论。 如果你留下了电子邮箱,我可能会通过 回复你。