面试八股¶
- Revised At:
2021-08
- Revised At:
2026-02
操作系统¶
进程、线程和协程 ¶
- 上下文
- 进程:
全部寄存器、栈(用户态内核态)、独立地址空间(TLB、CR3)
- 线程:
全部寄存器、栈(用户态内核态)
- 协程:
少量寄存器
进程切换最大的开销来自 TLB 的刷新和 CR3 ,简单来说都是由于独立的地址空间带来的。
Huge Page ¶
4K -> 2M
- Pros
TLB 能缓存的内存范围更大,访问内存更快
减少了页面数量,页表也少了一级,缺页中断的数量减少
能支持更大内存 存疑
- Cons
分配粒度大,利用率低
Swap、缺页开销大
透明巨型页。
死锁 ¶
讲一下操作系统死锁是如何发生的,以及如何解决死锁。
- 同时满足四个条件
互斥
持有并等待
不可剥夺
循环等待
- 避免死锁
固定锁顺序:避免循环依赖
超时释放:剥夺
避免嵌套用锁:避免循环依赖
粗粒度锁:避免循环依赖
非互斥锁(例如读写锁):减少/避免 互斥
无锁结构::D
计算机网络¶
网络连接五元组 ¶
源 IP 地址 (Source IP):发送方的 IP。
源端口号 (Source Port):发送方的进程端口。
目的 IP 地址 (Destination IP):接收方的 IP。
目的端口号 (Destination Port):接收方的服务端口(如 HTTP 的 80 端口)。
传输层协议 (Protocol):通常是 TCP 或 UDP。
TCP 三次握手 ¶
由 client 执行 connect(3) 触发。
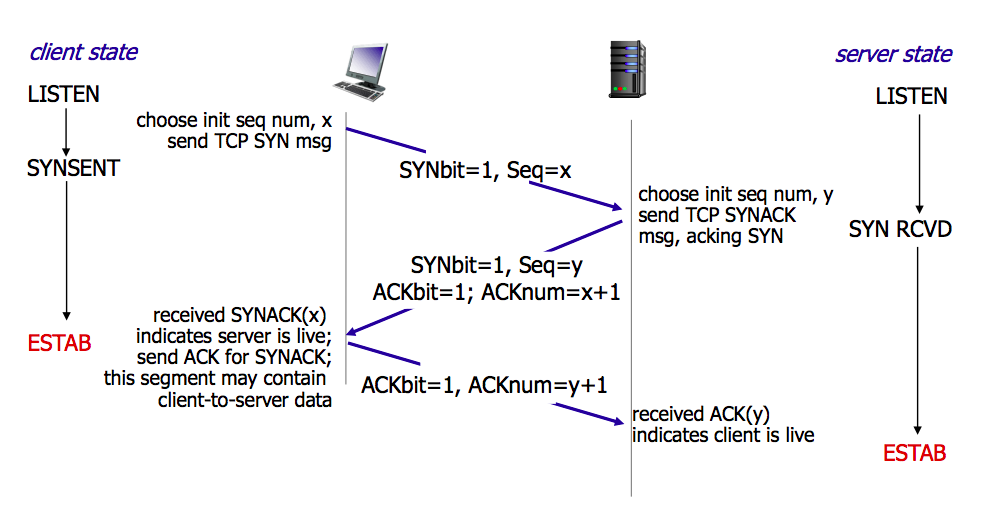
- 作用
确认双方的接收和发送能力是否正常
协商初始序列号,交换窗口大小等
- 为什么是三次:
全双工的连接需要确认两边的连通性都没有问题,需要双向都 SYN-ACK 一次。所以共四次通信。 但服务端收到 SYN 时可以将 ACK 由另一个方向的 SYN 捎带(piggyback),简化为三次握手。
- 流程:
SYN: 客户端发起 SYN
SYN-ACK: 服务端回应 ACK,并且向客户端发起 SYN
ACK(-DATA): 客户端回应 ACK,并且携带通信数据
- 异常
SYN 丢了
客户端定时重传
重传一定次数后返回错误给用户
Server 处理重复的 SYN
- 连接未关闭:
直接忽略
- 连接已关闭:
正常回复 SYN-ACK,由客户端 RST
备注
如果只有两次握手就无法处理这个情况
SYN-ACK 丢了
- Client:
在他看来就是 SYN 要重传
- Server:
等 Client 的 ACK,等来了重传的 SYN,转化成情况 2
ACK 丢了
Client 此时会认为连接已经建立,开始发数据。Server 还在 SYN-RECEIVED 状态, 等 ACK。
- Server:
超时后重传 SYN-ACK,重传一定次数后放弃(指数退避)
- Cilent:
直接开始发数据,Server 在 SYN-RCVD 状态收到数据时认为 Client 已经确认连接
SYN FLOOD
SYN Cookie,相当于把队列要存的信息作为 SeqNum 让 client 帮忙存
- Pros:
不需要分配内存空间
- Cons:
更多的计算,SYN cookie 容量有限导致不支持某些 TCP 高级特性
双方同时 SYN
P2P 场景可能出现,双方同时发 SYN-ACK,连接建立。
TCP 四次挥手 ¶
由任意一方执行 close(3) 触发。
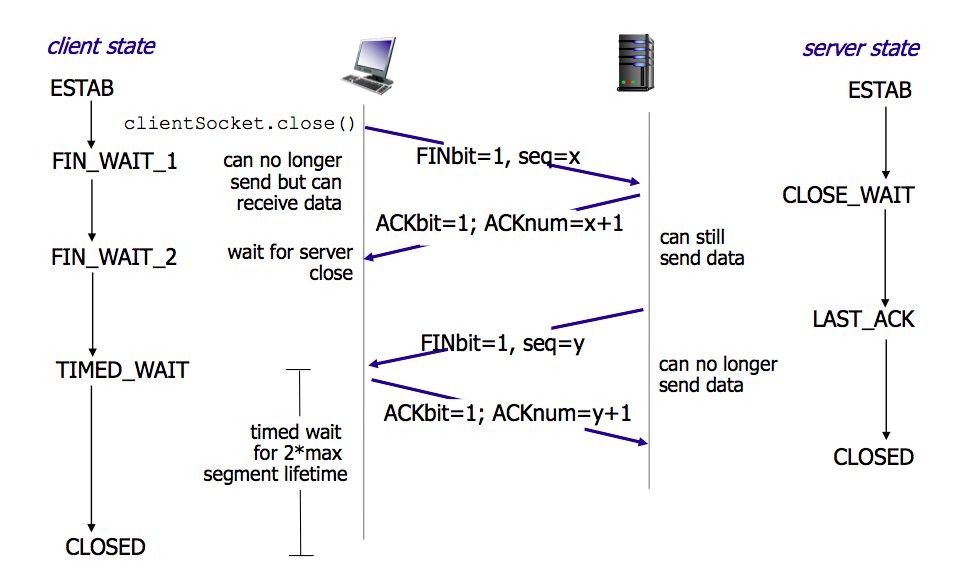
- 为什么是 4 次
TCP 是全双工的,有两条独立的数据流,两条都需要单独发 FIN 和 等 ACK,所以要四次。
也有三次的情况:如果被动方收到第一次 FIN 后,自己也没数据要发了,可以把 ACK 和 FIN 合并,变成三次挥手。
- 流程(假设客户端 close)
客户端发 FIN,关闭 client → server 的方向(不能发数据了,但还能收), 进入 FIN_WAIT_1 状态
服务器收到 FIN 回 ACK,客户端进入 FIN_WAIT_2,服务器进入 CLOSE_WAIT
提示
收到 FIN 时服务端可能还有数据要发,因此不总能把 FIN 和 ACK 合并
服务器发 FIN,关闭 server → client 的方向。服务器进入 LAST_ACK
客户端回 ACK,状态:客户端进入 TIME_WAIT,2MSL(Maximum Segment Lifetime,大约 4 分钟) 后 CLOSE,服务器收到 ACK 后进入 CLOSE
- 为什么要 TIME_WAIT
最后的 ACK(流程 4.)并没有送达保证(不能给 ACK 再加个 ACK 吧),如果有了 TIME_WAIT:
假设 ACK 成功送达,那么 Server 在未来就不会再发 FIN,Client 用有限的等待来验证事实:
The timeout value in TIME_WAIT is NOT used for retransmission purposes. When there is a timeout in TIME_WAIT, it is assumed that the final ACK was successfully delivered because the passive closer didn't retransmit FIN packets. So, the timeout in TIME_WAIT is just an amount of time after which we can safely assume that if the other end didn't send anything, then it's because he received the final ACK and closed the connection.
假设 ACK 丢失,有足够的时间让 Server 重传 FIN,继而 Client 重传 ACK,并 刷新 TIME_WAIT,并期待 1 成立
保留端口,等待旧连接的数据包在网路上完全消失(所以要持续 2MSL), 防止后面新建的连接导致数据错乱
- 异常
- TIME_WAIT 堆积
本端主动关连接导致的,可能会耗尽可用的端口。
连接复用,例如对于 HTTP 不要
Connection: close设计上让客户端主动关连接,客户端承担 TIME_WAIT 的成本
- CLOSE_WAIT 堆积
对端主动关连接,本端没有发第二个 FIN:基本是应用层没
close- Half Shudown
shudown(3) 而非 close(3),之发 FIN 不回收资源。
- TCP Keepalive
默认 7200s,用于回收 TCP 连接,并非给应用层使用。
UDP ¶
UDP Header:
struct udphdr {
__be16 source; // 源端口号 (16位)
__be16 dest; // 目的端口号 (16位)
__be16 len; // UDP长度 (首部+数据)
__sum16 check; // 校验和 (覆盖首部+数据+伪首部)
};
UDP 的核心贡献:给 IP 层加了端口,让数据能区分不同的应用(对应到进程)。 当然还有其他东西:自定义数据报长度(而非 IP 数据包)、可选的数据校验和。 其他一切交给上层。
- 和 TCP 区别
- TCP:
全双工,面向连接,可靠,一对一通信
- UDP:
无连接,不可靠,可多播、广播
常用于实时性要求高的场景:
实时通信(RTC/Real-Time Communication):视频通话、直播
HTTP3/QUIC
DNS
IoT
...
select、epoll、io_uring ¶
都是流行的 IO 多路复用接口。
- 📖 Select_(Unix)
是个单独的系统调用
- Pros
POSIX 兼容,跨平台
- Cons
获取活跃 fd 的方式是全量扫描,复杂度 \(O(n)\)
有最大 FD 限制(
FD_SETSIZE),且 fs_set 每次都要全量拷贝到内核
- 📖 Epoll
由三个系统调用
epoll_create、epoll_ctl、epoll_wait组成- Pros
底层为红黑树,复杂度 \(O(log_n)\),仅返回活跃的 fd
连接数:API 上无限制
通过 mmap 共享内存
边沿触发(异步推荐)、水平触发
- Cons
不支持文件 IO
做不到 syscall free,每个 fd 至少需要一次系统调用(
epoll_ctl)
- 📖 Io_uring
由两个用户和内存共享的环形队列组成:提交队列(SQ)和完成队列(CQ),应用程序吧 IO 请求通过 SQ 提交,内核将处理好的结果放入 CQ。
三种模式:中断、内核轮询(SQ POLL)、IO 轮询
- Pros
几乎完全零拷贝
支持批量提交
只需要至多三次系统调用 存疑 (mmap for )
- Cons
复杂
io_uring ¶
参见
学习工作流程 ⛺ shuveb/io_uring-by-example,实践上推荐使用 ⛺ axboe/liburing。
02_cat_uring¶
IORING_FEAT_SINGLE_MMAP¶
在看 02_cat_uring 有些疑惑:
在支持 IORING_FEAT_SINGLE_MMAP 的系统(Linux 5.14+ Linux 5.4+)上,可以只用一次 mmap 取到 sq cq 的虚拟地址,用同一个 base 配合 p.{sq,cq}_off 即可,如下:
struct io_uring_params p = {0};
void *sq_ptr, *cq_ptr;
// ...
ring_fd = io_uring_setup(QUEUE_DEPTH, &p);
// ...
sq_ptr = mmap(...)
if (p.features & IORING_FEAT_SINGLE_MMAP) {
cq_ptr = sq_ptr;
} else {
cq_ptr = mmap(...)
}
sring->head = sq_ptr + p.sq_off.head;
// ...
cring->head = cq_ptr + p.cq_off.head;
// ...
那要是用户不知道这个 feature 依然 mmap 两次呢?试了一下不会出错。
那之前初始化的 p.{sq,cq}_off 怎么就能适应这两种情况?
AI(DeepSeek、MiniMax M2.5)一番胡说八道,将信将疑调查一番结论是:
至少在支持 IORING_FEAT_SINGLE_MMAP 的系统上,sq 和 cq 的物理内存是连续的
struct io_rings { struct io_uring sq, cq; // ... }
p.cq_off.head并不是head相对于struct io_uring的偏移, 而是相对于struct io_rings的偏移,那么p.{sq,cq}_off应该都 对应同一个base ptrp->sq_off.head = offsetof(struct io_rings, sq.head); p->sq_off.tail = offsetof(struct io_rings, sq.tail); // ... p->cq_off.head = offsetof(struct io_rings, cq.head); p->cq_off.tail = offsetof(struct io_rings, cq.tail);
在
IORING_FEAT_SINGLE_MMAP情况下会有cq_ptr = sq_ptr;,没有问题, 在两次 mmap 的情况呢?{sq,cq}_ptr两个不同的虚拟地址其实会指向同一个物理地址, 从io_uring_mmap → io_uring_validate_mmap_request可见:switch (offset) { case IORING_OFF_SQ_RING: case IORING_OFF_CQ_RING: ptr = ctx->rings; break; // ... } // ... return ptr;
让 AI 写点代码验证一下:
io_uring_single_mmap.c#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <stdint.h> #include <inttypes.h> #include <sys/syscall.h> #include <sys/mman.h> #include <linux/io_uring.h> static inline uint64_t page_size(void) { return sysconf(_SC_PAGESIZE); } // See also https://man7.org/linux/man-pages/man5/proc_pid_pagemap.5.html uint64_t virt_to_phys(void *virt) { uint64_t addr = (uint64_t)virt, ps = page_size(); int fd = open("/proc/self/pagemap", O_RDONLY); if (fd < 0) { perror("open /proc/self/pagemap failed"); return 0; } uint64_t entry; uint64_t offset = (addr / ps) * sizeof(uint64_t); if (lseek(fd, offset, SEEK_SET) < 0 || read(fd, &entry, 8) != 8 || !(entry & (1ULL << 63))) { perror("read pagemap failed"); close(fd); return 0; } close(fd); return (entry & ((1ULL << 55) - 1)) * ps + (addr % ps); } void get_sq_cq_ptrs(void **sq, void **cq) { struct io_uring_params p = {0}; int fd = syscall(__NR_io_uring_setup, 1, &p); if (fd < 0) { perror("syscall io_uring_setup failed"); return; } int ssz = p.sq_off.array + p.sq_entries * sizeof(unsigned); int csz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe); *sq = mmap(0, ssz, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, fd, IORING_OFF_SQ_RING); *cq = mmap(0, csz, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, fd, IORING_OFF_CQ_RING); } int main() { void *sq, *cq; get_sq_cq_ptrs(&sq, &cq); // Test phys addr eq. uint64_t sq_phys = virt_to_phys(sq); uint64_t cq_phys = virt_to_phys(cq); printf("sq_ptr = %p -> phys = 0x%016" PRIx64 "\n", sq, sq_phys); printf("cq_ptr = %p -> phys = 0x%016" PRIx64 "\n", cq, cq_phys); printf("have same phys addr? %s\n", sq_phys == cq_phys ? "true" : "false"); // Test read and write. printf("*sq_ptr = %x\n", *(int *)sq); printf("*cq_ptr = %x\n", *(int *)cq); int v = 0x1234; printf("write 0x%x to sq_ptr, but not cq_ptr\n", v); *(int *)sq = v; printf("*sq_ptr = %x\n", *(int *)sq); printf("*cq_ptr = %x\n", *(int *)cq); }
$ gcc io_uring_single_mmap.c # ./a.out sq_ptr = 0x7f492a741000 -> phys = 0x000000028173e000 cq_ptr = 0x7f492a740000 -> phys = 0x000000028173e000 have same phys addr? true *sq_ptr = 0 *cq_ptr = 0 write 0x1234 to sq_ptr, but not cq_ptr *sq_ptr = 1234 *cq_ptr = 1234
s->sq_ring->array[] 和 s->sqes[] 的关系¶
submit_to_sq 有云:
next_tail = tail = *sring->tail;
next_tail++;
read_barrier();
index = tail & *s->sq_ring.ring_mask;
struct io_uring_sqe *sqe = &s->sqes[index];
// ...
sring->array[index] = index;
tail = next_tail;
// ...
此处 sring->array[index] = index 仅仅是巧合。
SQEs(Submission Queue Entries)描述一个 IO 请求,是单独分配的,
SQ 里只存 SQEs 的索引。而使用哪个 SQE 完全是用户决定的,只要正确填入 sq->array 即可。
而上面代码的 index、sring->{head,tail} 是指用来描述 sq->array 的。
sqes 只是图方便借用了它们。
这也是网上把 sq->array 称为间接数组的原因,要做二次索引才能拿到 SQE。
if (*sring->tail != tail) {...}¶
待处理
说是防御性编程 + 并发友好,我看着没什么卵用。
无锁?¶
- 队列指针所有权明确
The kernel controls head of the sq ring and the tail of the cq ring, and the application controls tail of the sq ring and the head of the cq ring.
—https://github.com/torvalds/linux/blob/v5.14/fs/io_uring.c#L136-L138
- 内存屏障
参看
02_cat_uring里的read,write_barrier的使用。如通过
read_barrier()保证读取 tail 时能看到内核的最新更新,从而安全地消费 CQE:void read_from_cq(struct submitter *s) { // ... head = *cring->head; // 用户控制所以不用 barrier do { read_barrier(); // 确保内核对 tail 的写入可见 if (head == *cring->tail) ...
Web¶
HTTPS 原理 ¶
- 对称加密
- Pros:
计算量小、加密速度快、加密效率高
- Cons:
需要协商密钥,也就无法避免密钥的传输
一对多通信时需要使用多对密钥
- 非对称加密
- Pros:
加密和解密使用不同的钥匙
- Cons:
计算量比较大(硬件加速卡)
- 通信过程
证书验证
数据传输阶段
非对称加密(协商对称密钥)
对称加密(传输数据)
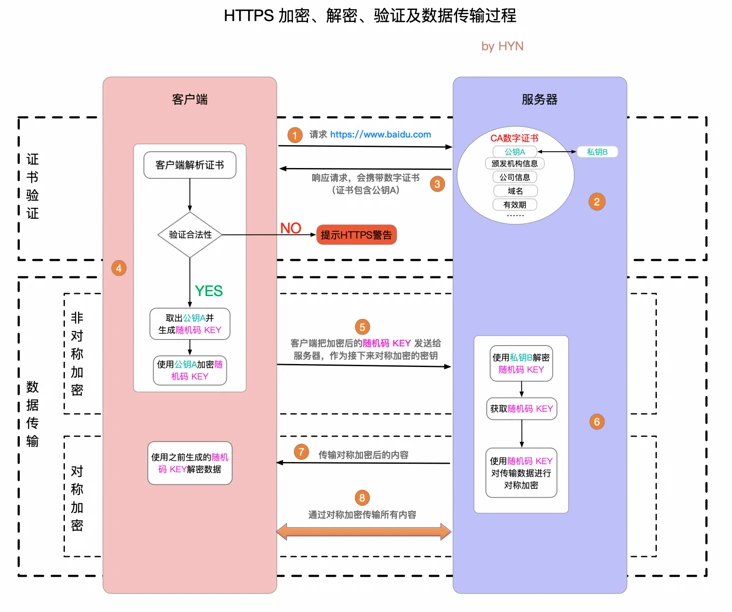
HTTPS 加密、解密、验证及数据传输过程¶
分布式¶
Map-Reduce 概述 ¶
- 流程
Split -> Map (Spill, Combiner) -> Shuffle -> Reduce
- Map 输出的分区内部为何有序
尽量把计算并行化,Reduce 收到可以进行归并
- 容错
前提:规模扩大导致机器异常成为常态(
1 - 故障概率*机器数量)Map:引入 Heartbeat、任务重新分配 Reduce :重新执行(S)
重新执行失败的任务
已拉取的数据需要重新拉取
Master 失败:
论文中的做法:终止作业,让用户重试
后来的实现中加入了 Master 的 HA(高可用)
- 数据局部性
"数据不动代码动",在拥有该文件区块的存储节点上执行 Map,而非传输到专用的计算节点
- 备用任务
大部分任务完成后,对久久不结束的任务启动备份任务,进行赛马
- Why Combiner?
Map 和 FP 里的 map 完全一致,是无状态的,wordcount 任务里,输入 "hello" 固定输出
("hello", 1)。在 Spill 落盘过程中由 Combiner 合并多个("hello", 1), 减少 Shuffle 的网络负担。
分布式 ID 生成 ¶
基本要求是全局唯一 —— 不冲突。
- UUID / 自己随机生成
- pros:
不依赖外部服务
- cons:
业务价值不大
不利于储存和索引
不能趋势递增 UUIDv6
- 单数据库自增 ID
- pros:
支持递增
- cons:
单点故障
不利于储存和索引
不能趋势递增
- 数据库集群自增 ID
- pros:
支持递增
不存在单点问题
- cons:
数据库集群方案麻烦
扩容麻烦
- 避免重复 ID
为不同实例制定不同的 ID 起始值,协商步长
- 分配号段
业界主流方式之一,就是一个 ID Quota Server,Client 每次取一段,用完再申请
- pros:
对数据库压力小
- cons:
要不集群化还是单点
朴素的实现中,没有把内存中的ID消费完重启服务,则会产生重复的ID
- Redis
优缺点同数据库
需要考虑持久化的问题
- Snowflake 算法
Timestamp + Machine ID + Data Center ID + Auto Increasement Num
- pros:
不依赖外部服务
便于链路追踪
支持递增
- cons:
int64 需要小心处理(前端)
CAP ¶
对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
分区容错性(Partition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择)
—— 📖 CAP定理
- P(分区容错性)是说这个系统要允许分区?
是的,如果要允许分区,则 A/C 不可兼得。而分布式系统总要支持分区。
网络分区(P)是必然发生的,所以通常是在CP(如ZooKeeper,牺牲可用性)和AP(如Eureka,牺牲强一致性,保证最终一致)之间权衡。
分布式锁 ¶
- 场景
分布式事务
避免重复工作
保证结果正确
- 额外特性
- 公平锁:
各个节点均摊锁带来的工作量
- 可重入:
已经持有锁的节点再锁住自己没意义
- 超时:
持有锁的节点故障应让锁得到释放
- 实现
mysql psql 关系型数据库:事务
redis redlock codis 非关系型数据库:SETNX (set if not exist)
etcd:CAS + Lease
chubby 专用的锁服务
分布式定时器 ¶
- 实现
公平的分布式锁实现:etcd
环形队列/时间轮
- 时间轮
高效的定时器实现,适用于海量定时任务。
结构是多个不同时间级别(分钟级、秒级、毫秒级)的环状队列。
一致性级别 ¶
- 强/线性一致性
任何一次读都能读到某个数据的最近一次写的数据
系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致
- 最终一致性
系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态
- 顺序一致性
所有的进程都以相同的顺序看到所有的修改。
读操作未必能够及时得到此前其他进程对同一数据的写更新,但是每个进程读到的该数据不同值的顺序却是一致的。
关系型数据库¶
数据库范式 ¶
提示
太晦涩了,实用价值缺,很多凭直觉就行。
- 1NF
原子性,属性都不可再分
- 2NF
非主属性完全依赖主属性
- 3NF
非主键属性之间独立无关
- BCNF
任何属性(包括非主属性和主属性)都不能被非主属性所决定。
ACID ¶
- A:
Atomicity 原子性
- C:
Consistency 一致性
- I:
Isolation 隔离性
- D:
Durability 持久性
事务隔离级别 ¶
- Read Uncommitted:
允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
- Read Committed:
只能读取到已经提交的数据。Oracle 等多数数据库默认都是该级别。 不可重复读:在同一事务中多次读取同个字段可能不一致(被其他事务 commit 了)
- Repeated Read:
可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。 在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读。 幻像读:字段数据没变,但统计结果可能变化(
COUNT(*))- Serializable:
完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
索引 ¶
- 作用
提高查询效率
实现数据库约束
- 代价
需要额外的空间
插入、更新和删除记录时,需要同时修改索引
- 类型
哈希索引:等值查询效率高,不支持区间查询
顺序索引:查询效率高(二分),只适用于静态存储引擎
多路搜索树索引
- 按结构分类
聚簇索引:索引指向一整列
非聚簇索引:索引仅指向字段,要查整列需根据该字段查表(回表)
- B 树和 B+ 树
多路平衡搜索树。
树分叉多,深度低,减少磁盘 IO
- 区别
B+ 树非叶子节点不存数据,叶子节点用链表串联,对范围查询友好
- 局部性原理
B/B+树的节点大小 = 磁盘页大小(通常4KB或16KB)
分表与分片|_|¶
行存储列存储 ¶
维度 |
行存储 (Row-oriented) |
列存储 (Column-oriented) |
|---|---|---|
数据组织 |
按行连续存储,同一行的所有列在一起 |
按列连续存储,同一列的所有值在一起 |
磁盘I/O |
即使只查询几列,也要读取整行 |
只读取查询涉及的列,I/O极小 |
压缩率 |
较低(一行内数据类型多样) |
极高(同一列数据类型相同,重复值多) |
写入性能 |
快(一次写入一行) |
慢(一行数据要分散到多个列文件) |
更新/删除 |
快(原地更新) |
极慢(需要重写整列) |
点查询 (SELECT * FROM table WHERE id=1) |
快(直接定位行) |
慢(需要读取多列再组装) |
聚合查询 (SELECT AVG(age) FROM table) |
慢(扫描大量无用数据) |
极快(只扫描目标列) |
适用场景 |
OLTP(在线交易) |
OLAP(数据分析、数仓) |
- 行存:
传统 RDS
- 列存:
ClickHouse、Hive(Parquet)
- 混合:
OceanBase、TiDB
HTAP ¶
HTAP: Hybrid Transactional(T)/Analytical(A) Processing
让一份数据同时支持 TP 和 AP,实时写入、实时分析。
并发控制 ¶
数据库中的并发控制的任务是确保在多个事务同时访问数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。
- 乐观锁
假设不冲突,冲突则回滚:
乐观锁假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
乐观并发控制多数用于数据争用不大、冲突较少的环境中,这种环境中,偶尔回滚事务的成本会低于读取数据时锁定数据的成本,因此可以获得比其他并发控制方法更高的吞吐量。
—— 📖 乐观并发控制
- 悲观锁
串行的事务控制:
悲观锁可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作读某行数据应用了锁,那只有当这个事务把锁释放,其他事务才能够执行与该锁冲突的操作。
悲观并发控制主要用于数据争用激烈的环境,以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
—— 📖 悲观并发控制
- 公平锁
多个线程按照申请锁的顺序去获得锁
- Pros:
所有的线程都能得到资源,不会饿死在队列中
- Cons:
吞吐量下降,队列里面除了第一个线程,其他的线程都会阻塞,唤醒开销大
- 非公平锁
多个线程不按照申请锁的顺序去获得锁,而是同时直接去尝试获取锁
- Pros:
效率稍高
- Pros:
可能导致饥饿
- MVCC
乐观的版本控制:
每个事务读到的数据项都是一个历史快照(snapshot)并依赖于实现的隔离级别。写操作不覆盖已有数据项,而是创建一个新的版本,直至所在操作提交时才变为可见
MVCC使用时间戳 (TS), 或“自动增量的事务ID”实现“事务一致性”。MVCC可以确保每个事务(T)通常不必“读等待”数据库对象(P)。这通过对象有多个版本,每个版本有创建时间戳 与废止时间戳 (WTS)做到的。
事务Ti读取对象(P)时,只有比事务Ti的时间戳早,但是时间上最接近事务Ti的对象版本可见,且该版本应该没有被废止。
事务Ti写入对象P时,如果还有事务Tk要写入同一对象,则(Ti)必须早于(Tk),即 (Ti) < (Tk),才能成功。[2]
MVCC可以无锁实现。
—— 📖 多版本并发控制
架构¶
服务重试¶
重试的前提是幂等。
幂等性:多次调用结果一致
重试策略:指数退避
限流器 ¶
固定时间窗口计数
滑动时间窗口计数
滑动日志 / Sliding log: 记录具体的时间戳,精度比滑动时间窗口好,可用 Redis zset 实现
Token Bucket:令牌规律放入桶中,请求消耗令牌,令牌可以攒着应对突发流量
Leaky Bucket:请求放入桶中,以固定速率漏出
参见
流量整形
负载均衡 ¶
- 方向
客户端侧
反向代理侧
- 原理
Round Robin
传统的哈希取模算法
一致性哈希
基于连接数
基于会话
- 硬件
F5
- 软件
Nginx 7 层
envoyproxy 4 层、7 层
HAproxy
LVS(Linux Virtual Server)4 层
一致性哈希 ¶
解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系
用环状哈希解决:新节点加入时数据映射关系大规模改变的问题
用虚拟节点解决:节点过少导致的数据倾斜
查找距离这个对象的 hash 值最近的节点的 hash(在排好序的哈希数组里二分),即是这个对象所属的节点
Golang¶
MGP 模型 ¶
- 线程模型
- N:1:
可以很快的进行上下文切换,但是不能利用多核系统(multi-core systems)的优势
- 1:1:
能够利用机器上的所有核心的优势,但是上下文切换非常慢,因为不得不使用系统调用
- M:N:
可以快速进行上下文切换,并且还能利用你系统上所有的核心的优势。主要的缺点是它增加了调度器的复杂性
- M.P.G
- M:
Machine,OS 线程
- P:
Processor,逻辑处理器,可以把它看作在一个单线程上运行代码的调度器的一个本地化版本,携带一个 Goroutine 的 runqueue
- G:
Goroutine
P 就是
runtime.GOMAXPROCS里的 PROCS.- 为什么 M 和 P 要分开?
解耦了"执行能力"和"调度上下文"
如果正在运行的 M1 为某种原因需要阻塞的时候,可以把 P 和当前的 M2 解绑,让 P 去找新的 M2 来继续执行其他 G。
Go 程序要在多线程上运行的原因就是因为要处理系统调用,哪怕
GOMAXPROCS等于 1- G 队列
每个 G 拥有自己的无锁本地队列,仅在 Stealing 时需要加锁。Runtime 另有一个带锁的全局队列。
- Runqueue stealing
当 P 本地队列空时,从其他 P 偷取或者从全局队列偷取。
垃圾回收¶
经典 GC 算法 ¶
- 经典的 GC 算法
引用计数(reference counting)
标记-清扫(mark & sweep)
节点复制(Copying Garbage Collection)
分代收集(Generational Garbage Collection)。
- 引用计数
- Pros
渐进式的,能够将内存管理的开销分布到整个程序之中
易于实现
回收速度快
- Cons
不能处理循环引用(引入强弱引用可破)
降低运行效率
free list 实现的话不是 cache-friendly
- 标记-清扫
内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是 STW,转而执行垃圾回收程序。垃圾回收程序对所有的存活单元进行一次全局遍历确定哪些单元可以回收。算法分两个部分:标记(mark)和清扫(sweep)。标记阶段表明所有的存活单元,清扫阶段将垃圾单元回收。
- Pros
支持循环引用
运行时开销小
- Cons
需要 STW
- 三色标记
是「标记-清扫」的变种,对标记阶段进行了改进:
起初所有对象都是白色
从根出发扫描所有可达对象,标记为灰色,放入待处理队列
从队列取出灰色对象,将其引用对象标记为灰色放入队列,自身标记为黑色
重复 3,直到灰色对象队列为空。此时白色对象即为垃圾,进行回收
- Pros
能够让用户程序和 标记 并发的进行(?),减少 STW 的时间
备注
标记期间有新的对象分配/释放怎么办?
通过设置写屏障(write barriar)记录下来,标记完 STW 再检查一遍
备注
Golang GC 使用三色标记法
- 节点复制
- Pros
无内存碎片
allocate 简单,通过递增自由空间指针即可
- Cons
总有一半的内存空间处于浪费状态
基于追踪的垃圾回收算法(标记-清扫、节点复制)一个主要问题是在生命周期较长的对象上浪费时间(长生命周期的对象是不需要频繁扫描的)。同时,内存分配存在这么一个事实:
most object die young [Ungar, 1984]
- 分代收集
分代垃圾回收算法将对象按生命周期长短存放到堆上的两个(或者更多)区域,这些区域就是分代(generation)。对于新生代的区域的垃圾回收频率要明显高于老年代区域。
分配对象的时候从新生代里面分配,如果后面发现对象的生命周期较长,则将其移到老年代,这个过程叫做 promote。随着不断 promote,最后新生代的大小在整个堆的占用比例不会特别大。收集的时候集中主要精力在新生代就会相对来说效率更高,STW 时间也会更短。
- Pros
性能优
- Cons
实现复杂
Go 的垃圾回收 ¶
- 何时触发 GC 检测
- 被动触发:
在堆上分配大于 32K byte 对象时触发 GC 检测
- 主动触发:
调用
rumtime.GC()
- GC 触发条件
forceTrigger || memstats.heap_live >= memstats.gc_trigger当前堆上的活跃对象大于我们初始化时候设置的 GC 触发阈值
memstats.gc_trigger在gcinit()时被设置- 两次 mark
从 root 开始遍历,标记为灰色。遍历灰色队列
re-scan 全局指针和栈。因为 mark 和用户程序是并行的,所以在过程 1 的时候可能会有新的对象分配,这个时候就需要通过写屏障(write barrier)记录下来。re-scan 再完成检查
- 两次 STW
GC 将要开始的一些准备工作,比如 enable write barrier
re-scan,如果这个时候没有 STW,那么 mark 将无休止
- 写屏障
收集 mark 期间的对象分配情况
- Dive in to code
- gcBgMarkStartWorkers:
为每个 P(线程上的本地调度器)启动一个 gcMarkWoker
- gcDrain:
Mark 阶段的标记代码主要实现
- GAB
Go 生态下的字节跳动大规模微服务性能优化实践 - 文章 - 开发者社区 - 火山引擎
GAB: 为 noscan 对象新增一个 Per-G 的 Bump pointer 风格的分配路径,GAB bucket 本身可以给 GC 跟踪和回收。为处理少量活跃对象需要额外实现 Copy GC 难点可能在处理栈扩展和 map 扩容等 reallocte 的场景。
- 1.26 GreenTea
The Green Tea Garbage Collector - The Go Programming Language
Track by page, not by object. 优化了空间局部性,对缓存友好,更容易被现代 CPU 优化。
内存管理¶
逃逸分析: go run with -gcflags '-m -l'
- 如何得知变量是分配在栈(stack)上还是堆(heap)上?
不需要关心,由 go 内部决定
- 多级分配器
- mcache:
per-P cache,可以认为是 local cache,不需要加锁
- mcentral:
全局 cache,mcache 不够用的时候向 mcentral 申请。
- mheap:
当 mcentral 也不够用的时候,通过 mheap 向操作系统申请。
sync.Mutex ¶
互斥、自旋(正常状态)、公平(饥饿状态)。
- 自旋
不 park,直接 CAS 抢
mutexWoken位,而非被唤醒后再抢- 限制条件
P > 0
自旋次数有限
P 的 runq 为空:没有待调度的 G
- 公平
等待时间超过
starvationThresholdNs饥饿模式下 Unlock,仅唤醒第一个 waiter,一定能抢锁成功
还是蛮复杂的,记个差不多就行。
sync.RWMutex ¶
- 读写问题的三大类
- 读优先
占有锁时,后来的读进程可以立即获得锁
- Pros:
可以提高并发性能(后来的读进程不需要等待)
- Cons:
读进程过多,会导致写进程一直处于等待中,出现写饥饿现象
- 写优先(RWMutex)
优先是指如果有写进程在等待锁,会阻止后来的进程获得锁
- Pros:
写饥饿的问题
不区分优先级
Golang 的实现是写的互斥锁 + 读计数器,感觉有点别扭。
一个我认为应当 detect 但实际上没还有的错误用法:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mu sync.RWMutex
go func() {
fmt.Println("Lock")
mu.Lock()
fmt.Println("Locked")
defer func() {
fmt.Println("Unlock")
mu.Unlock()
fmt.Println("Unlocked")
}()
time.Sleep(5 * time.Second)
}()
time.Sleep(100 * time.Millisecond)
go func() {
time.Sleep(100 * time.Millisecond)
fmt.Println("RUnlock")
mu.RUnlock()
fmt.Println("RUnlocked")
}()
fmt.Println("RLock")
mu.RLock()
fmt.Println("RLocked")
}
Defer¶
小坑点:参数是提前求值的
struct runtime._defer 组成了一条 defer link list。
- <1.13:
堆上分配
- >=1.13:
栈上分配
- <1.14:
Open coded
&^ 操作符 ¶
日常是很少用上,标准库代码里见得多。
Bit clear,a &^ b == a & ^b。
数据竞争¶
sync.Cond 的虚假唤醒 ¶
因为 condition 的判断是用户代码,在 Wait() 返回之后,因此只能要求用户用忙等的方式等到 condition 满足的时刻:
Because c.L is not locked when Wait first resumes, the caller typically cannot assume that the condition is true when Wait returns. Instead, the caller should Wait in a loop:
c.L.Lock() for !condition() { c.Wait() } // ... make use of condition ... c.L.Unlock()
版本变更 ¶
- 1.18
PDQSort
- 1.19
SetMemoryLimit
- 1.24
- "Remove" Core Types
-
让
[]byte和string共享操作成为可能。 - Swiss Table
-
SIMD 友好
- 1.25
- GreenTea GC
...
- JSONv2
https://go.dev/blog/jsonv2-exp
Steam-friendly,支持 Options
云原生/虚拟化¶
Docker ¶
- 共享内核
Docker image 里不包含内核,程序共享宿主机内核
- Namespace
用 unshare(1) 创建
- Mount:
每个容器能看到不同的文件系统层次结构
- UTS:
每个容器可以有自己的 hostname 和 domainame
- IPC:
每个容器有其自己的 sysvipc(7) 和 mq_overview(7) 队列,只有在同一个 IPC namespace 的进程之间才能互相通信
- PID:
每个 PID namespace 中的进程可以有其独立的 PID,也使得容器中的每个进程有两个 PID
- Network:
每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端口号等
- User:
每个 container 可以有不同的 user 和 group id;一个 host 上的非特权用户可以成为 user namespace 中的特权用户
- Cgroup
通过 sysfs
/sys/fs/cgroup控制,创建目录,并指定 PID,如:/sys/fs/cgroup/cpu/docker/03dd196f415276375f754d51ce29b418b170bd92d88c5e420d6901c32f93dc14or
systemd-cgls- Resource limitation:
限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization:
优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting:
一些审计或一些统计,主要目的是为了计费。
- Control:
挂起进程,恢复执行进程。
AUFS、OverlayFS、VFS、Brtfs
- OverlayFS
lowerdir、uperdir、merged,其中lowerdir是只读的image layer,其实就是rootfs,
lowerdir是可以有多个目录。upperdir则是在lowerdir之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容器数据更改都发生在这里层, 对比示例中的C。最后 merged 目录是容器的挂载点,也就是给用户暴露的统一视角
- 进程模型
- dockerd:
和 docker-cli 通信,管理镜像
- containerd:
管理容器
- container-shim:
通过 runC 运行容器
流处理¶
Flink CheckPoint¶
Operator State Keyed State
PLER vs Flink¶
CheckPoint
UDF
Watermark
逻辑计划优化¶
常量折叠
列裁剪
乱序元素¶
- URL:
- Watermark:
根据流的情况制定开启和关闭策略
- allowLateNess:
延迟窗口关闭时间
- sideOutPut:
指定窗口已经彻底关闭后,就会把所有过期延迟数据放到侧输出流,让用户决定如何处理
大语言模型¶
Transformer ¶
context FNN KV cache
Vibe Coding 方法论 ¶
cs146S https://www.zhihu.com/question/1991174455536395775/answer/2008337875469613040
https://www.zhihu.com/question/1951716962645288920/answer/2007657176265663018
AI Infra¶
向量数据库
For Kong¶
- Lua/LuaJIT
语法、特性
C API
Co-routine
- GraphQL
...
Nginx OpenRestry
Envoy